
「もっと自分好みの絵柄を出したい」「特定のキャラクターをAIに描かせたい」そう思ったことはありませんか?
Stable Diffusionを使っていると、どうしても既存のモデルだけでは表現しきれない部分が出てくるものです。そんな時に役立つのが「追加学習」。自分のパソコン(ローカル環境)で特定の画風やキャラを学習させれば、まさに思い通りの画像を生成できるようになります。
ただ、正直なところ「追加学習って難しそう」「プログラミング知識が必要なんでしょ?」と不安に感じる方も多いですよね。実は、現在の技術なら、ツールを使えば以前よりずっと手軽に挑戦できるようになっています。
この記事では、Stable Diffusionの追加学習をローカル環境で行うための手順を、専門用語をできるだけ噛み砕いて解説します。私自身も最初はエラー続きで躓きましたが、ポイントさえ押さえれば必ず自分だけのモデルが作れるようになりますよ。一緒に「自分専用のAI」を育てていきましょう!
- Stable Diffusionの追加学習(LoRA)の仕組みとメリット
- ローカル環境で学習させるために必要なPCスペックと準備
- 質の高い学習データ(画像)の集め方と加工のコツ
- 専用ツールを使った具体的な学習手順と設定のポイント
Stable Diffusionの追加学習をローカルで行うための基礎知識と準備
自分だけのモデルを作るなんて、少しワクワクしますよね。ここではまず、追加学習を成功させるために絶対に知っておきたい基礎知識と、必要な準備についてお話しします。
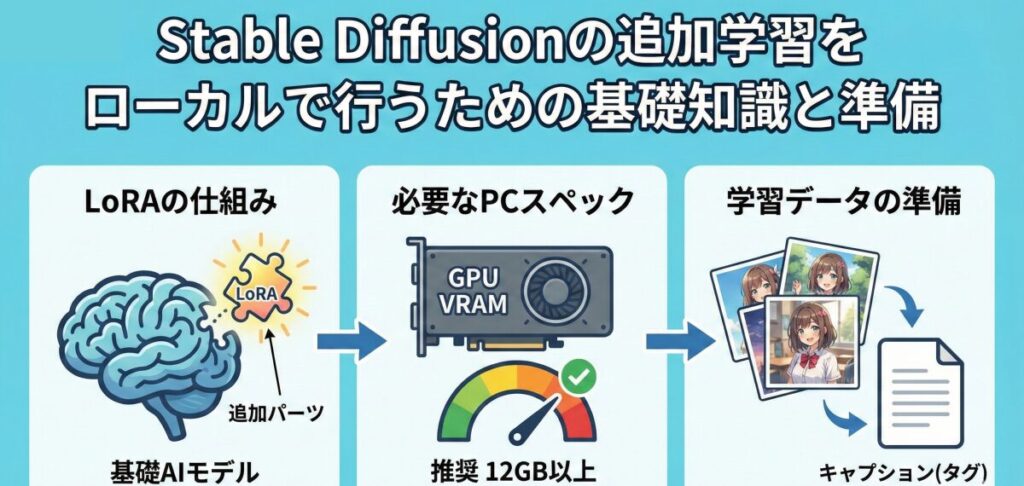
Stable Diffusion 追加学習 LoRAとは?
まずは「LoRA(ローラ)」について理解しておきましょう。Stable Diffusionの追加学習と言えば、現在はほとんどの場合このLoRAを指します。
LoRAは「Low-Rank Adaptation」の略で、ものすごく簡単に言うと「既存のAIモデルにくっつける追加パーツ」のようなものです。本来、AIモデル全体を学習させようとすると、スーパーコンピューター並みの性能が必要になります。しかし、LoRAなら学習する範囲をギュッと絞るため、一般的な家庭用ゲーミングPCでも学習が可能なんです。
この技術のおかげで、私たちは数GBもある巨大なモデルデータを一から作る必要がなくなりました。数十MB程度の小さなファイル(LoRAファイル)を作るだけで、画風やキャラを自由自在に変更できるのです。
Stable Diffusion ローカル環境 モデル学習に必要なスペック
「私のPCでもできるのかな?」というのは一番気になるところですよね。ローカル環境で学習させる場合、何よりも重要なのがGPU(グラフィックボード)のVRAM容量です。
学習は画像の生成以上にPCへ負荷をかけます。推奨スペックを以下の表にまとめましたので、自分のPCと照らし合わせてみてください。
| 項目 | 最低スペック | 推奨スペック | 備考 |
| GPU (VRAM) | 8GB | 12GB以上 | ここが一番重要! NVIDIA製必須 |
| メモリ (RAM) | 16GB | 32GB以上 | 学習中の動作安定に影響 |
| ストレージ | SSD空き50GB | SSD空き100GB | HDDだと読み込みが遅く時間がかかる |
もしVRAMが8GBギリギリの場合、設定をかなり工夫しないとエラーで止まってしまうことがあります。快適に学習を回したいなら、やはり12GB以上のVRAMを持つGeForce RTX 3060や4060Ti(16GB版)などが安心です。
Stable Diffusion 学習データ 作り方のコツ
スペックが足りていても、肝心の「学習データ(画像)」が良くなければ、AIは賢くなりません。実は、学習の成功失敗の8割は「素材画像の質」で決まると言っても過言ではないのです。
学習データを作る際のポイントは以下の通りです。
- 枚数: キャラクターなら15枚〜30枚程度で十分です。多ければ良いというわけではなく、質の悪い画像が混ざると逆効果になります。
- バリエーション: 正面だけでなく、横顔、後ろ姿、アップ、全身など、多角的な視点の画像を用意しましょう。
- 背景: 可能であれば背景が白い画像や、背景を切り抜いた透過画像を使うと、キャラクターの特徴をより正確に捉えてくれます。
また、画像の解像度はバラバラでもツール側で調整できますが、基本的には「512×512」や「768×768」などの正方形、あるいは長方形にリサイズしておくと学習効率が上がります。
Stable Diffusion LoRA学習画像を集める際の注意点
学習に使う画像を集める際、「どんな画像でもいいの?」と迷うかもしれません。
結論から言うと、「自分が生成したい絵柄や被写体がハッキリ写っている画像」を選んでください。例えば、ピンボケしている写真や、他のキャラクターが重なって写っているイラストはNGです。AIが「どれを学習すればいいの?」と混乱してしまうからです。
ここで注意したいのが著作権です。個人的に楽しむ範囲(ローカル環境での利用)であれば許容されるケースが多いですが、学習させたモデル(LoRA)を配布したり販売したりする場合は、元の画像の権利関係をしっかり確認する必要があります。トラブルを避けるためにも、権利的にクリーンな画像や、自分で撮影・描画した素材を使うのが一番安全です。
AI画像 学習 させる スマホの写真は使える?
「スマホで撮った写真でも学習できるの?」という質問もよく頂きます。答えは「YES」です。
最近のスマートフォンのカメラは非常に高画質なので、素材として十分に機能します。例えば、自分のペットや特定のフィギュア、あるいは自分自身の顔を学習させたい場合、スマホで様々な角度から撮影した写真を使うのが手っ取り早いでしょう。
ただし、「学習処理そのもの」をスマホで行うのは現状ほぼ不可能です。あくまで「素材集めはスマホ、学習処理はハイスペックPC」という役割分担になります。スマホで撮影した写真は、PCに転送してからトリミングやリサイズなどの加工を行ってくださいね。



Stable Diffusionの追加学習をローカルで実践する具体的な手順
準備が整ったら、いよいよ実際に学習をさせていきましょう。ここでは、多くの人が利用している定番ツールを使った手順を解説します。
Stable Diffusion 追加学習方法には「Kohya_ss」がおすすめ
ローカル環境での追加学習には、「Kohya_ss GUI」というツールが世界標準と言えるほど普及しています。
本来、学習を行うには黒い画面(コマンドプロンプト)に複雑な命令文を打ち込む必要がありますが、Kohya_ssを使えば、ボタンや入力ボックスのある画面(GUI)で直感的に操作できるからです。
導入には「Python」や「Git」といったプログラム環境のインストールが必要ですが、ネット上には初心者向けの導入スクリプト(インストーラー)も配布されています。まずはこれをご自身のPCにインストールすることから始めましょう。「Kohya_ss インストール」で検索すると、詳細な手順がたくさん出てきますよ。
Stable Diffusion 学習させる 方法とステップ
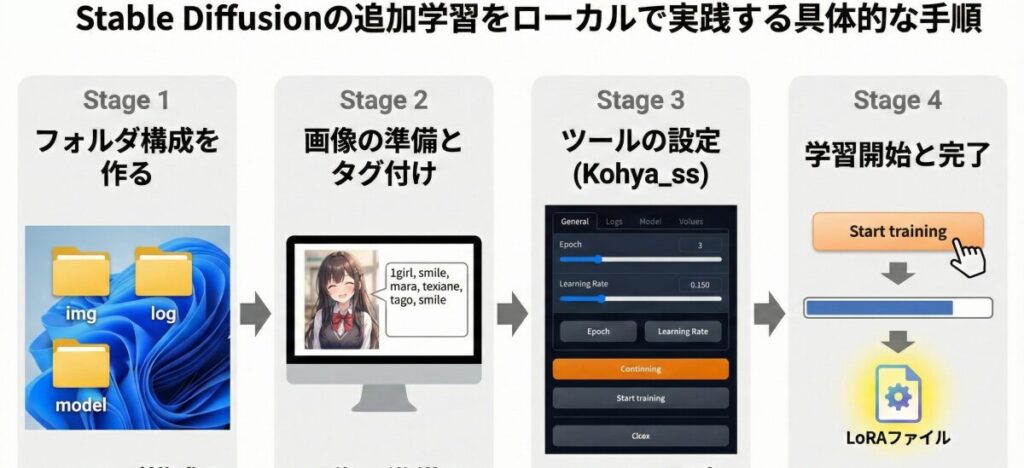
Kohya_ssが起動できたら、以下のステップで学習を進めます。
- フォルダ構成を作る:デスクトップなどに新規フォルダを作り、その中に「img(画像用)」「log(記録用)」「model(完成品用)」の3つのフォルダを用意します。
- 画像の準備とキャプション付け:「img」フォルダの中に、さらに「10_character」のような名前のフォルダを作り、そこに画像とキャプションファイル(.txt)を入れます。キャプションとは、その画像に何が写っているかをAIに教えるテキストデータです(例:1girl, smile, blue hairなど)。
- Kohya_ssの設定:ツール上で画像フォルダの場所を指定し、学習回数(Epoch)や学習率(Learning Rate)を設定します。最初はデフォルト設定か、ネットで共有されている「おすすめ設定」を真似してみるのが近道です。
- 学習開始ボタンを押す:設定が終わったら「Start training」ボタンを押します。PCのファンが唸りを上げ始めますが、完了するまでじっと待ちましょう。
Stable Diffusion 学習させる 写真とイラストの違い
ここで一つポイントなのが、「実写(写真)」を学習させる場合と、「イラスト」を学習させる場合では、最適な設定が少し異なるということです。
例えば、写真のようなリアル系モデルを作りたい場合、学習データには高解像度な写真を用い、AIモデルも「Stable Diffusion v1.5」や「SDXL」の実写系モデルをベースに選ぶ必要があります。一方、アニメ調のイラストを学習させるなら、ベースモデルもアニメ系(Anythingなど)を選ぶのが定石です。
また、写真の場合は「肌の質感」や「光の当たり方」が複雑なため、イラストよりも少し多めに学習ステップ数を取った方が、リアルな結果になりやすい傾向があります。
質の高いモデルを作るための「タグ付け」の重要性
学習成功の鍵を握るのが、前述した「キャプション(タグ付け)」の精度です。
Kohya_ssには自動でタグ付けをしてくれる機能もついていますが、完璧ではありません。例えば、キャラクターの特徴である「猫耳」をAIが「帽子」と誤認識してしまうことがあります。このまま学習させると、猫耳を帽子として覚えてしまうため、生成時にうまくいきません。
面倒でも、テキストファイルの中身を確認し、「学習させたい特徴(例:猫耳)」はタグとして残し、「学習させたくない要素(例:背景の壁)」はタグから消すか、そのままにしてAIに『これは背景だよ』と認識させるといった調整が必要です。ここを丁寧に行うだけで、完成するLoRAのクオリティが劇的に向上します。
学習したLoRAの使い方と確認
学習が終わると、「model」フォルダに「.safetensors」という拡張子のファイルが出来上がります。これがあなただけのLoRAファイルです。
これをStable Diffusion(WebUIなど)の所定のフォルダ(models/LoRA)に入れ、プロンプトに <lora:ファイル名:1> と記述して画像を生成してみてください。学習させたキャラや画風が反映されていれば大成功です!
もし「全然似ていない」場合は学習不足(アンダーフィッティング)、「絵が崩れている」場合は学習させすぎ(オーバーフィッティング)の可能性があります。その時は、学習率を下げたり、画像の枚数を調整したりして、再チャレンジしてみましょう。この試行錯誤こそが、AI学習の醍醐味でもあります。
ここで、「もっと本格的に、仕事レベルでAIを使いこなしたい」と感じた方にお伝えしたいことがあります。独学での追加学習は、エラーの対処やパラメータ調整でどうしても時間がかかってしまうものです。
もし、あなたが「最短で高品質なモデルを作りたい」「身につけたスキルを副業や仕事に繋げたい」と考えているなら、「バイテック生成AIスクール」のような専門スクールを検討するのも一つの賢い選択肢です。
バイテック生成AIスクールは、単なるツールの使い方だけでなく、ControlNetなどの高度な制御技術や、今回紹介したStable Diffusionの追加学習を実務レベルで活用するノウハウまで網羅しています。さらに、ポートフォリオ作成や案件獲得のサポートまであるため、「趣味」を「収益」に変えるための確実なステップアップが可能です。独学に行き詰まった時の選択肢として、頭の片隅に置いておいてくださいね。

AIを使って副業を始めたいけれど、「独学だと挫折しそう」「本当に案件が取れるか不安」という方は、実務と収益化に特化したスクールを検討してみるのも近道です。
\ ※完全オンライン・スマホで1分で予約完了 /
実際に、未経験から月5万円の収益化を目指せるバイテック生成AIというスクールについて、評判やカリキュラムの実態を詳しく検証してみました。
▼続きはこちらの記事で解説しています

まとめ
- Stable Diffusionの追加学習にはLoRAが主流で手軽である
- ローカル環境での学習はGPUのVRAM容量(推奨12GB以上)が鍵となる
- 学習データは量より質が重要で15〜30枚程度から始めると良い
- 画像は正方形(512pxなど)にリサイズすると学習効率が上がる
- 著作権に配慮し権利的にクリーンな画像を使用すべきである
- スマホで撮影した写真もPCに取り込めば優秀な素材になる
- 学習ツールはGUIで操作できるKohya_ssが世界的な定番である
- 学習手順はフォルダ作成、タグ付け、設定、実行の流れで行う
- 画像ごとにキャプション(タグ)を正確に付けることが精度向上の肝だ
- 実写とイラストではベースモデルや設定のコツが微妙に異なる
- 学習不足ならステップ数を増やし、崩れるなら学習率を下げる
- 完成したLoRAはプロンプトで呼び出して使用することができる
- 最初は失敗してもパラメータ調整を繰り返すことで改善できる
- 独学が難しい場合は専門スクールで体系的に学ぶのも近道である
- 自分だけのモデルを作ることで生成AIの楽しさが何倍にも広がる
参考資料・出典
本記事の執筆にあたり、技術的な正確性と信頼性を担保するため、以下の一次情報および公的機関・専門機関の資料を参照しています。
- LoRA(Low-Rank Adaptation)の技術基盤と論文
LoRA: Low-Rank Adaptation of Large Language Models (arXiv)
※本記事で解説した追加学習技術「LoRA」の仕組みと、なぜ軽量な計算リソースで学習が可能かを実証した、Microsoft研究チームによる原著論文(一次情報)です。 - Stable Diffusion モデル仕様・ライセンス情報
Stability AI 公式サイト
※Stable Diffusionの開発元であるStability AI社の公式情報です。各モデル(v1.5, SDXL等)の正確な仕様や、商用利用に関するガイドラインの出典元となります。 - AI学習用ハードウェア(GPU)の技術仕様
NVIDIA AI コンピューティング
※ローカル環境での学習に必須となるGPU(GeForce RTXシリーズ)のVRAM仕様や、計算処理技術(CUDA)に関するNVIDIA公式の技術資料です。
.jpg)








