
- 「1人の女の子を描きたいだけなのに、なぜか双子や三つ子になってしまう……」
- 「横長の画像を作ろうとすると、画面の端にもう一人現れる!」
Stable Diffusionを使っていると、こんな現象に悩まされることはありませんか?
プロンプトにしっかり「1girl(一人の少女)」と書いているのに、AIが勝手に人数を増やしてしまう。
これ、実は初心者の方が必ずと言っていいほどぶつかる「あるある」な壁なんです。
でも、安心してください。
この現象には明確な原因があり、設定を少し見直すだけで、ピタッと一人だけに固定することができるようになります。
さらに、キャラクターを一人に固定する技術は、その後の「動画生成」においても非常に重要なスキルになります。
この記事では、意図せず複数人になってしまう原因とその解決策を、専門用語少なめで優しく解説していきます。
思い通りの構図で、最高の一枚を作れるようになりましょう!
この記事を読むと以下のことが分かります
- プロンプトや解像度設定を見直して、キャラクターを「一人だけ」に固定する具体的な方法
- 横長画像や高画質化(Hires.fix)をした際に、勝手に人数が増えるのを防ぐテクニック
- ControlNetなどの機能を使って、思い通りの配置にキャラクターを描写するコツ
- 習得したキャラクター固定技術を活かして、Stable Video Diffusionなどで動画化するステップ
Stable Diffusionで一人だけ描きたいのに複数人になる原因と完全攻略
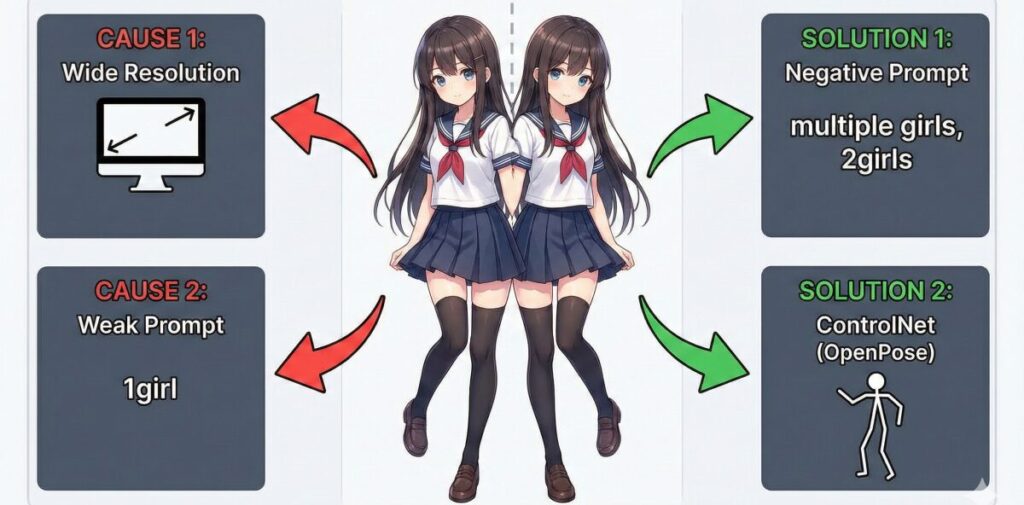
まずは、なぜ「一人だけ」と指示しているのに人数が増えてしまうのか、その原因と対策を見ていきましょう。
AIは基本的に「キャンバスの空白を埋めたい」という性質を持っています。
ここを理解すれば、コントロールは意外と簡単です。
プロンプトとネガティブプロンプトの基本設定
もっとも基本的な対策は、やはりプロンプト(呪文)の強化です。
AIに対して「絶対に一人だよ!」と念押しする必要があります。
具体的には、通常のプロンプトに 1girl や solo を入れるだけでなく、それらを強調することが大切です。
例えば (1girl:1.3) のようにカッコと数字で重み付けをすると、AIはその指示をより強く意識します。
一方で、やってはいけないことを指示する「ネガティブプロンプト」も重要です。
ここに以下のキーワードを入れてみてください。
multiple girls(複数の少女)2girls(2人の少女)more than one person(1人より多い)
これを入力するだけで、AIは「あ、複数はダメなんだな」と理解してくれます。
現在の私は、テンプレートとして必ずこれらをネガティブプロンプトに入れるようにしています。
縦横比と高解像度化が招く分裂を防ぐ
「正方形だと大丈夫なのに、横長にすると増える」
これは、Stable Diffusionが学習した画像のサイズに関係しています。
AIのモデル(特にSD1.5系)は、基本的に512×512ピクセルで学習されています。
そのため、例えば横幅を900ピクセルなどに広げると、AIは「おっ、スペースが余ってるな。もう一人描けそうだな」と判断してしまいがちです。
これを防ぐには、Hires.fix(高解像度化補助)の設定を見直すのが効果的です。
最初は512×512や512×768などの「AIが得意なサイズ」で生成し、その後にHires.fixを使って拡大するようにしましょう。
最初から大きなサイズで生成しようとすると、体が崩れたり人数が増えたりする原因になります。
また、Hires.fixを使う際の「Denoising strength(ノイズ除去強度)」が高すぎると(0.7以上など)、拡大中に絵が書き換わって人が増えることがあるので、0.5〜0.6程度に抑えるのがコツです。
ControlNetで構図と人数を強制的に指定する
プロンプトや設定だけではどうしても制御できない……。
そんな時に頼りになる最強のツールがControlNet(コントロールネット)です。
ControlNetの「OpenPose」という機能を使えば、棒人間でポーズを指定できます。
「ここに一人の棒人間」を配置して生成すれば、AIはその骨格に従って絵を描くしかないため、物理的に二人目を描くことができなくなります。
「難しそう……」と感じるかもしれませんが、導入してしまえば操作は直感的です。
これで「ガチャ」のような運任せの生成から卒業し、狙った通りの構図を作れるようになります。
Stable Diffusion 動画 アニメ化でも重要な基礎
実は、今回紹介している「人数を一人に固定する技術」は、静止画だけでなくStable Diffusion 動画 アニメ化の際にも非常に重要になります。
動画を作る時、元となる絵が不安定だと、動かした瞬間にキャラクターが分裂したり、消えたりしてしまうからです。
静止画の段階で完璧にコントロールできてこそ、クオリティの高い動画が作れます。
基礎をしっかり固めておくことが、結果的に動画作成の近道になるのです。



Stable Diffusionで一人だけ描いた絵が動画でも複数人になるのを防ぐ方法
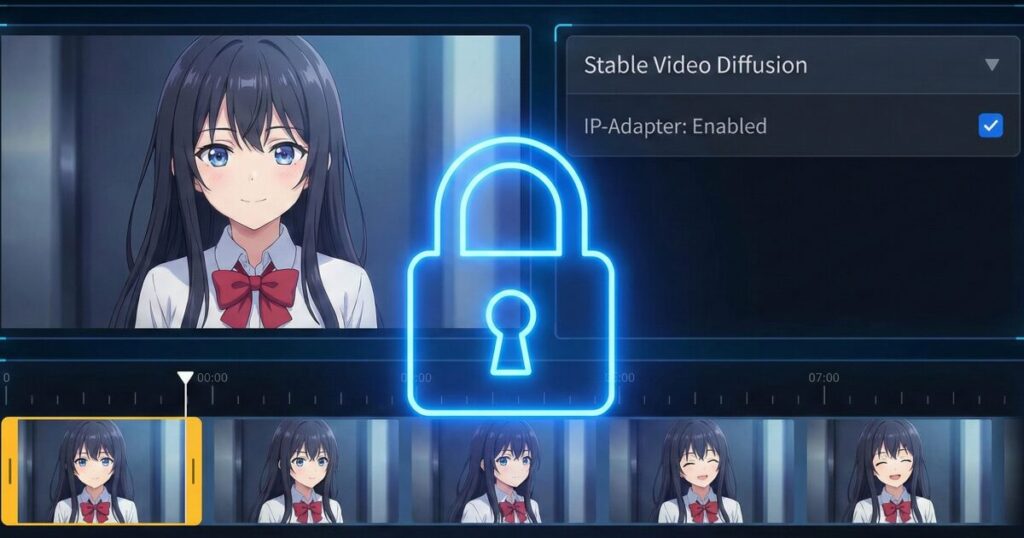
静止画でキャラクターを一人に固定できたら、次はそのキャラクターを動かしてみたくなるのが人情ですよね。
ここでは、最新の動画生成技術に触れつつ、動画になっても「一人だけ」をキープするコツを紹介します。
Stable Video Diffusionで自然な動画を作る
現在、画像から動画を作る「Image to Video」の分野で注目されているのが、Stable Video Diffusion(SVD)です。
これはStability AI社が公式に出しているモデルで、たった一枚の画像から、風になびく髪や瞬きなどの自然な動きを生成してくれます。
使い方はシンプルで、生成したお気に入りの「一人だけの画像」をSVDに読み込ませるだけ。
ただし、ここでも注意が必要です。
SVDは「動き」を予測して生成するため、動きを大きくしすぎると、背景から二人目の人物が湧き出てくるようなエラーが起きることがあります。
最初は「Motion Bucket Id」などのパラメータを控えめにして、微細な動きから試すのがおすすめです。
Stable Diffusion 動画 一貫性を保つための技術
動画を作る上で最大の課題と言われるのが、Stable Diffusion 動画 一貫性の問題です。
フレームが進むごとに顔が変わってしまったり、一人のキャラが分裂してしまったりすることを指します。
これを防ぐには、先ほど紹介したControlNetがここでも活躍します。
動画生成においては、「ControlNet Tile」や「IP-Adapter」という機能を併用することで、元の画像の情報を強力に維持したまま動かすことができます。
「このキャラはこの一人だけ!」とAIに強く認識させ続けることで、動画の最後まで破綻せずに生成できるようになります。
Stable Diffusion 動画生成 ローカル環境とスペック
動画生成は静止画よりもはるかにパソコンへの負荷がかかります。
Stable Diffusion 動画生成 ローカル環境で快適に行うためには、それなりのマシンスペックが必要です。
Stable Diffusion 動画 スペックの目安としては以下の通りです。
- GPU(グラフィックボード): VRAM 12GB以上(RTX 3060 12GB版やRTX 4070など)
- メモリ: 32GB以上推奨
特にVRAM(ビデオメモリ)が重要で、ここが少ないと動画生成中にエラーで止まってしまうことが多いです。
もしこれからPCを用意するなら、VRAMの容量を最優先にチェックしてみてください。
Stable Diffusion 動画 作り方のステップ
最後に、Stable Diffusion 動画 作り方の基本的な流れを整理します。
- 静止画生成: プロンプトやControlNetを駆使して、「一人だけ」の完璧な画像を作る(ここが最重要!)。
- 拡張機能の導入: WebUIにSVDやAnimateDiffなどの拡張機能をインストールする。
- 設定調整: 生成した画像を読み込み、フレーム数や動きの大きさを設定する。
- 動画生成: スペックに合わせて解像度などを調整し、生成ボタンを押す。
このように、動画作りは「静止画生成の延長線上」にあります。
静止画のスキルを高めることが、そのまま動画のクオリティアップに直結するわけです。
ただ、こういった一連の流れや、ControlNetのような高度な機能を独学ですべてマスターするのは、正直かなり時間がかかります。
エラーが出た時に何が原因か分からず、何時間も悩んでしまうことも珍しくありません。
もしあなたが、「趣味の範囲を超えて、もっと効率的にハイクオリティな作品を作りたい」「あわよくばこのスキルを仕事にしたい」と考えているなら、バイテック生成AIスクールのような専門の環境で学ぶのも一つの手です。
このスクールでは、Stable DiffusionやControlNetの実践的な使い方はもちろん、実務レベルの動画制作ノウハウまで体系的に教えてくれます。
プロの講師に直接質問できる環境があれば、独学の何倍ものスピードでスキルが身につくはずです。

AIを使って副業を始めたいけれど、「独学だと挫折しそう」「本当に案件が取れるか不安」という方は、実務と収益化に特化したスクールを検討してみるのも近道です。
\ ※完全オンライン・スマホで1分で予約完了 /
実際に、未経験から月5万円の収益化を目指せるバイテック生成AIというスクールについて、評判やカリキュラムの実態を詳しく検証してみました。
▼続きはこちらの記事で解説しています

Stable Diffusionで一人だけ描く・動かす まとめ
それでは、今回の内容をまとめます。
- AIは空白を埋めたがる性質があるためプロンプトで人数指定を強調することが大切
- ネガティブプロンプトに「multiple girls」などを入れるのが基本の対策
- 横長画像はAIがスペースを誤認しやすいため512ベースで生成後に拡大すると良い
- Hires.fixのDenoising strengthを上げすぎると分裂の原因になる
- ControlNetのOpenPoseを使えば骨格を指定して物理的に一人に固定できる
- 静止画で完全に制御できていないと動画化した際にさらに破綻しやすくなる
- Stable Video Diffusion(SVD)を使えば静止画から高品質な動画が作れる
- 動画生成時も動きのパラメータを大きくしすぎると人物が増えることがある
- 動画の一貫性を保つにはIP-Adapterなどの維持機能を活用するのがコツ
- ローカル環境で動画を作るならVRAM 12GB以上のGPUスペックが推奨される
- 動画制作のフローはまず「完璧な静止画」を作ることから始まる
- 高度な技術やエラー解決は独学よりも専門スクールで学ぶ方が効率的
- まずはプロンプトの見直しから始めて徐々にControlNetなどに挑戦するのがおすすめ
- 焦らず設定を一つひとつ確認すれば必ず思い通りの「一人」を描けるようになる
参考文献・関連リンク
この記事は、以下の公式研究および学術論文に基づいて執筆されています。
- High-Resolution Image Synthesis with Latent Diffusion Models
Stable Diffusionの基礎技術である「潜在拡散モデル」に関する原著論文です。学習解像度と生成画像の構図の関係性など、画像が分裂する根本的な仕組みが理論的に解説されています。
High-Resolution Image Synthesis with Latent Diffusion Models – arXiv - ControlNet (Adding Conditional Control to Text-to-Image Diffusion Models)
記事内で推奨している、ポーズ指定による人数制御技術「ControlNet」の公式論文です。入力画像(棒人間など)を用いて生成結果を強力に制御する手法が詳述されています。
Adding Conditional Control to Text-to-Image Diffusion Models – arXiv - Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Stability AI社による動画生成モデル「Stable Video Diffusion」の公式研究発表です。画像から動画を生成する際の一貫性保持や、モデルのアーキテクチャに関する一次情報です。
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets – Stability AI
.jpg)








