
- 「自分だけのオリジナルキャラクターを作りたいけれど、プロンプトだけではどうしても限界がある」
- 「特定の画風や衣装をAIに覚えさせたいけれど、やり方が難しそうで手が出せない」
もしあなたが、今こんな風に悩んでいるなら、この記事はあなたのためのものです。
Stable Diffusionを使っていると、どうしても「あと少し、ここがこうなればいいのに」という場面に出くわしますよね。
実は、その悩みは「追加学習」を行うことで解消できる可能性が高いです。
「学習させる」と聞くと、なんだかプログラミングの知識が必要な難しい作業のように感じるかもしれません。
ただ、現在はツールが進化していて、初心者の方でも手順さえ覚えれば、自分好みのAIモデルを作ることができるようになっています。
自分の描いた絵や、撮影した写真をAIに学ばせることで、生成される画像のクオリティやコントロール性は劇的に向上します。
ここでは、Webライターとして多くのAIツールに触れてきた私が、Stable Diffusionに学習させるための具体的な方法や、失敗しないためのコツを、専門用語をなるべく使わずに優しく解説していきます。
この記事を読み終わる頃には、あなたも「自分だけのAI」を作る第一歩を踏み出せているはずです。
この記事を読むと、以下の点について理解が深まります。
- Stable Diffusionにおける「学習(LoRA)」の仕組みとメリット
- 初心者でも失敗しない学習用データの集め方と加工の手順
- ローカル環境で追加学習を行うための具体的なツールと設定
- 版権キャラクターの扱いや学習リセットなど、運用上の注意点
Stable Diffusionに学習させるための基礎知識と準備

Stable Diffusionは、最初から膨大な量の画像を学習していますが、それだけではあなたの好みに100%マッチするとは限りません。
そこで重要になるのが、特定の要素を追加で覚えさせる「学習」というプロセスです。
まずは、この学習が具体的にどのような仕組みで行われるのか、そして準備すべきことについて整理していきましょう。
Stable Diffusionの学習とは?仕組みを解説
そもそも、Stable Diffusionにおける「学習」とは何を指すのでしょうか。
単純に言えば、「AIに新しい教科書を渡して、特定の知識を詳しくさせること」です。
通常の状態(ベースモデル)が「広く浅く知っている百科事典」だとしたら、追加学習は「特定の漫画や画風に特化した専門書」を読み込ませるイメージに近いでしょう。
これを理解した上で、大きく分けると学習には「ファインチューニング(Dreambooth)」と「LoRA(Low-Rank Adaptation)」という2つの種類があります。
ファインチューニングはモデル全体を書き換えるため、非常に高性能ですが、その分データ容量が巨大になり、高性能なパソコンが必要です。
一方で、LoRAはモデルの一部だけを変更する方法で、ファイルサイズも軽く、扱いやすいのが特徴です。
現在の画像生成AI界隈では、このLoRAを使った学習が主流となっています。
初心者が学習させるならLoRA一択
私が初心者の方に強くおすすめするのは、間違いなくLoRAの作成です。
なぜなら、LoRAは学習にかかる時間が短く、パソコンへの負荷も比較的少ないからです。
例えば、数ギガバイトあるモデル全体を再学習させるのは大変ですが、LoRAなら数十メガバイトのファイルを作るだけで済みます。
さらに言えば、LoRAは「着せ替え」のように使えるのも大きなメリットです。
「今日はアニメ風の画風LoRAを使おう」「次はリアルな質感のLoRAに切り替えよう」といった具合に、ベースモデルはそのままで、必要な時だけ学習データを適用できるのです。
Stable Diffusion Web UIを使えば、この切り替えもワンクリックで行えます。
このように言うと、「難しそう」と思っていたハードルが少し下がるのではないでしょうか。
学習データの作り方とダウンロード
質の高い学習をさせるために最も重要なのが、「学習データ(教師画像)」の準備です。
いくら高性能なGPUを使っていても、読み込ませる画像の質が悪ければ、良いLoRAは完成しません。
ここでは、以下のポイントを意識してデータを集めてみてください。
- 枚数: 最低でも15〜20枚程度は用意しましょう。多すぎても学習時間が伸びるだけなので、最初は20枚前後がおすすめです。
- 画質: ノイズが少なく、学習させたい対象がはっきりと映っている画像を選びます。
- 背景: 可能であれば、白背景やシンプルな背景の画像を用意するか、切り抜き加工を行うと精度が上がります。
また、自分で画像を用意するのが難しい場合は、CivitaiやHugging Faceといったサイトから、他のユーザーが作成した学習データ(LoRA)をダウンロードして試してみるのも一つの手です。
「どんな画像で学習させると、どんな結果になるのか」を知るための参考にもなります。
ただし、ダウンロードしたデータを利用する際は、商用利用が可能かどうかなど、ライセンスを必ず確認してください。
Web UIとローカル環境での追加学習
実際に学習を行う場所についても触れておきましょう。
基本的には、ご自身のパソコン(ローカル環境)に環境を構築するのが一番です。
Google Colabなどのクラウドサービスを使う方法もありますが、現在は規制が厳しくなっていたり、有料枠が必要だったりするため、ローカル環境での学習が最も安定しています。
学習を実行するためのツールとしては、「Kohya_ss GUI」というツールが現在世界標準として使われています。
これは、コマンド(文字)を打ち込まなくても、ボタン操作や数値入力だけで学習設定ができる非常に便利なソフトです。
Stable Diffusion Web UI (Automatic1111) とは別のソフトですが、連携して使うことで真価を発揮します。
学習に必要なPCスペックの目安
| 項目 | 推奨スペック | 備考 |
| GPU (グラフィックボード) | NVIDIA GeForce RTX 3060以上 | VRAM 12GB以上あると快適です |
| メモリ (RAM) | 16GB以上 (32GB推奨) | 学習中は多くのメモリを消費します |
| ストレージ | SSD (空き容量50GB以上) | 学習データやモデルの保存に必要です |
もし、あなたのPCスペックが足りない場合は、無理をせずクラウドサービスの利用を検討するか、あるいは生成AIのプロフェッショナルから直接学ぶ環境を整えるのも良い選択肢です。



Stable Diffusionで実際に学習させる手順とコツ
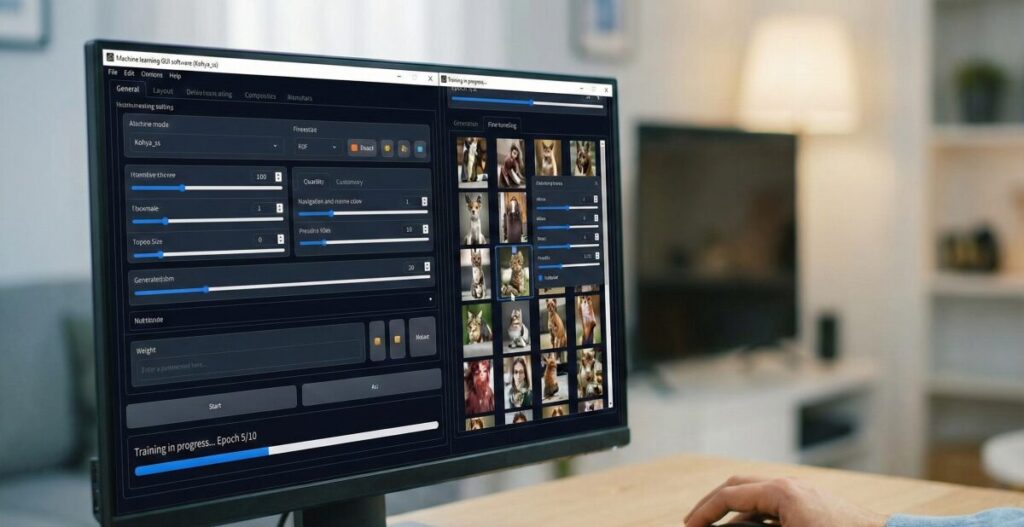
基礎知識が頭に入ったところで、ここからはより実践的な内容に入っていきましょう。
実際に学習をスタートさせると、思わぬエラーが出たり、期待通りの画像が出なかったりすることがあります。
そうした壁にぶつからないための具体的な手順と、クリエイターとして知っておくべき注意点をお伝えします。
ローカル環境での学習ステップ
Kohya_ss GUIを使ったローカル学習の大まかな流れは以下の通りです。
手順が多く感じるかもしれませんが、一度やってしまえばルーチンワークになります。
- 画像の前処理: 用意した画像をすべて同じサイズ(例:512×512, 768×768など)にリサイズします。
- キャプション付け: それぞれの画像に何が描かれているか、テキストファイル(タグ)を作成します。「1girl, blue eyes, school uniform」のように、AIに正解を教える作業です。
- フォルダ構成: 学習用画像、正解画像、ログ保存先などのフォルダをルール通りに作成します。
- パラメータ設定: 学習回数(Epoch数)や学習率などを設定します。最初はデフォルト設定に近い値から始めると失敗が少ないです。
- 学習開始: ボタンを押して、処理が終わるのを待ちます。PCの性能によりますが、LoRAであれば数十分〜数時間で完了します。
このとき、「キャプション付け」を丁寧に行うことが、成功への一番の近道です。
AIは画像と文字の関連性を学習するため、ここが適当だと、せっかくの追加学習も効果が半減してしまいます。
版権キャラを学習させる際のリスク
ここで、非常にデリケートですが大切な話をしなければなりません。
版権キャラクターの学習についてです。
アニメやマンガのキャラクターをAIに学習させ、LoRAを作成すること自体は、技術的には可能です。
そして、個人で楽しむ範囲(私的利用)であれば、直ちに違法となる可能性は低いとされています。
しかし、それを配布したり、販売したり、あるいは生成した画像をSNSで公開して収益を得たりすることは、著作権侵害のリスクが非常に高くなります。
「みんなやっているから大丈夫」と安易に考えるのは危険です。
あくまで「ファン活動の一環」として、個人のPCの中で楽しむ範囲に留めるか、あるいは完全にオリジナルのキャラクターや画風の学習に注力することをおすすめします。
クリエイターとして長く活動したいのであれば、権利関係には誰よりも敏感であるべきです。
学習リセットや失敗しないためのポイント
- 「学習させたけれど、なんだか絵が崩れてしまう」
- 「元のモデルの良さが消えてしまった」
このような現象を「過学習(Overfitting)」と呼びます。
熱心に勉強しすぎて、応用が利かなくなってしまった状態ですね。
もし過学習が起きてしまった場合、残念ながら学習済みのLoRAファイルを後から修正することはできません。
学習リセット、つまり設定を見直して「最初から学習し直す」必要があります。
これを防ぐためには、学習の途中で定期的にモデルを保存(Save every N epochs)する設定にしておくのがコツです。
例えば10回学習する予定なら、2回目、4回目、6回目…とデータを残しておけば、「8回目が一番綺麗だったな」と後から選ぶことができます。
失敗は成功の母です。
一度で完璧なLoRAを作るのは、プロでも難しいことです。
何度もパラメータを調整し、トライアンドエラーを繰り返すことが、理想の画像を生成するための唯一の道です。
生成AIを仕事にするならスクールも検討
ここまで解説してきた通り、Stable Diffusionの学習は非常に奥が深く、面白い世界です。
ただ、独学で進めていると「なぜエラーが出るのか分からない」「もっと高品質な商用レベルの画像を作りたい」という壁にぶつかることも少なくありません。
特に、これからAIスキルを副業や本業に活かしたいと考えているなら、尚更です。
私であれば、もし本気でスキルアップを目指すなら、プロの指導を受けることを検討します。
例えば、バイテック生成AIスクールのような、実務特化型のオンラインスクールはご存知でしょうか。
ここは単にツールの使い方を教えるだけでなく、「どうやって収益化するか」「仕事として成立させる品質とは何か」を徹底的に学べるのが特徴です。
ControlNetを使った精密な画像生成や、LoRA作成の高度なテクニックなど、独学では習得に時間がかかる部分を、最短ルートで身につけることができます。
案件獲得のサポートまであるので、「趣味で終わらせたくない」という方には、まさにうってつけの環境と言えるでしょう。
AI技術は日々進化していますから、確かな知識を持つメンターがいることは、大きな武器になります。

AIを使って副業を始めたいけれど、「独学だと挫折しそう」「本当に案件が取れるか不安」という方は、実務と収益化に特化したスクールを検討してみるのも近道です。
\ ※完全オンライン・スマホで1分で予約完了 /
実際に、未経験から月5万円の収益化を目指せるバイテック生成AIというスクールについて、評判やカリキュラムの実態を詳しく検証してみました。
▼続きはこちらの記事で解説しています

Stable Diffusion学習のまとめ
最後に、ここまで解説してきた内容を要約します。
これから学習にチャレンジする方は、ぜひこのリストを見返しながら作業を進めてみてください。
学習のポイントまとめ
- Stable Diffusionの学習にはLoRAが最適である
- LoRAは容量が軽く、着せ替え感覚で利用できる
- 学習データは最低15〜20枚程度用意する
- 画像の質とキャプション付けが完成度を左右する
- 背景はシンプルなものか切り抜き加工推奨である
- 学習環境はローカルPCに構築するのが安定的である
- GPUのVRAMは12GB以上あると快適に動作する
- Kohya_ss GUIが学習ツールのスタンダードである
- 版権キャラの学習は私的利用の範囲に留めるべきである
- 商用利用時は著作権やライセンス確認が必須である
- 過学習を防ぐために途中経過のモデルも保存する
- 失敗したら設定を変えてリセット(再学習)する
- 既存のLoRAをCivitaiなどで探すのも有効である
- プロのスキルを学ぶなら専門スクールも検討する
- トライアンドエラーを楽しむ心が一番大切である
あなただけのオリジナルモデルが完成すれば、画像生成の楽しさは何倍にも広がります。
最初は難しく感じるかもしれませんが、焦らず一つずつステップを進めていきましょう。
あなたのクリエイティブな活動を心から応援しています。
この記事の信頼性を支える参考資料・公的情報源
- LoRA技術の基礎となる学術論文
arXiv (Cornell University):LoRA: Low-Rank Adaptation of Large Language Models
(出典:記事内の「学習の仕組み」において、LoRA技術がどのようにモデルのパラメータを効率化しているかを示す、Microsoft研究チーム等による技術的な一次情報源です。) - Stable Diffusion 公式開発元情報
Stability AI Official Website
(出典:Stable Diffusionのベースモデルの仕様や、商用利用におけるライセンス規約(CreativeML Open RAIL-M等)を確認するための開発元による公式情報です。)
.jpg)








